
基于低性能MCU的DP深度学习可研
待续...
待续...

# -*- coding: utf-8 -*-"""Created on Sun Dec 29 19:21:08 2019@原作者: xiuzhang Eastmount CSDN@修改作者:ChanRa1n修正问题:TensorFlow版本低,学习速率过高,修正为0....
//转自 #include "stdio.h" #include "stdlib.h" #include "time.h" #include "math.h"...

硬件介绍及实现的功能 本项目实现了一个口罩检测的系统,采用M5Stack提供的M5Stack UnitV2设备,并以该设备为核心。UnitV2设备以Sigmstar SSD202D为核心,通过GC2145摄像头采集图像信息,使用OpenCV和腾讯的开源N...

本教程为本站原创,转载请注明本网站链接,否则视为侵权!如果朋友还没有安装Armbian,或者怎么折腾也折腾不好,请直接翻到文章最后下载img文件!教程中碰到出错的地方,可以重复运行代码尝试!其他的ArmV7 32位的也可以参考本文,图片分类速度:1.1帧/秒,每张图片耗时约900ms,生产用途应该是...
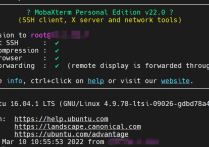
第一部分、仅使用HPS进行计算第一步、通过ssh链接至开发板第二步、解决apt-get存在的问题chmod 644 /usr/lib/sudo/sudoers.so && chown -R root /usr/li...
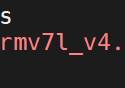
步骤一、链接ssh并上传NPU SDK 步骤二、插入NPU,并给NPU赋予权限sudo chmod 666 /dev/sg*步骤三、修改最大字节数find /sys/devices/ -name max_sectors -exec sh -c 'ech...
 蜀ICP备19035584号-1 | | 川公网安备 51142202000123号 版权所有 © 2019-2024, 陈语ChanRa1n(网站仅用于学习和教育目的). 由MyFPGA智慧中心驱动,主站访问统计(360奇安信),Email:chenyu@myfpga.cn
蜀ICP备19035584号-1 | | 川公网安备 51142202000123号 版权所有 © 2019-2024, 陈语ChanRa1n(网站仅用于学习和教育目的). 由MyFPGA智慧中心驱动,主站访问统计(360奇安信),Email:chenyu@myfpga.cn